

根据state of AI,随着人工智能市场的火热,英伟达自2020年推出A100以来,不断缩短下一代数据中心GPU的交付周期,同时显著提升TFLOPs性能(TFLOPs是衡量计算能力的单位,表示每秒执行的浮点运算次数。在高性能计算、超级计算机、图形处理单元以及深度学习等领域,TFLOPs是一个重要的性能指标,用于评估系统的计算能力。这个指标对于科学模拟、大数据分析、机器学习等需要大量计算的任务至关重要,TFLOPs越高,说明硬件在处理浮点运算方面的能力越强)。从A100到H100的时间缩短了60%,而从H200到GB200的周期又缩短了80%。在此期间,TFLOP性能增加了6倍。据悉,许多大型云公司正在大量采购GB200系统,其中微软的订单在70万至140万之间,谷歌为40万,亚马逊为36万。传闻OpenAI至少也购买了40万台GB200。
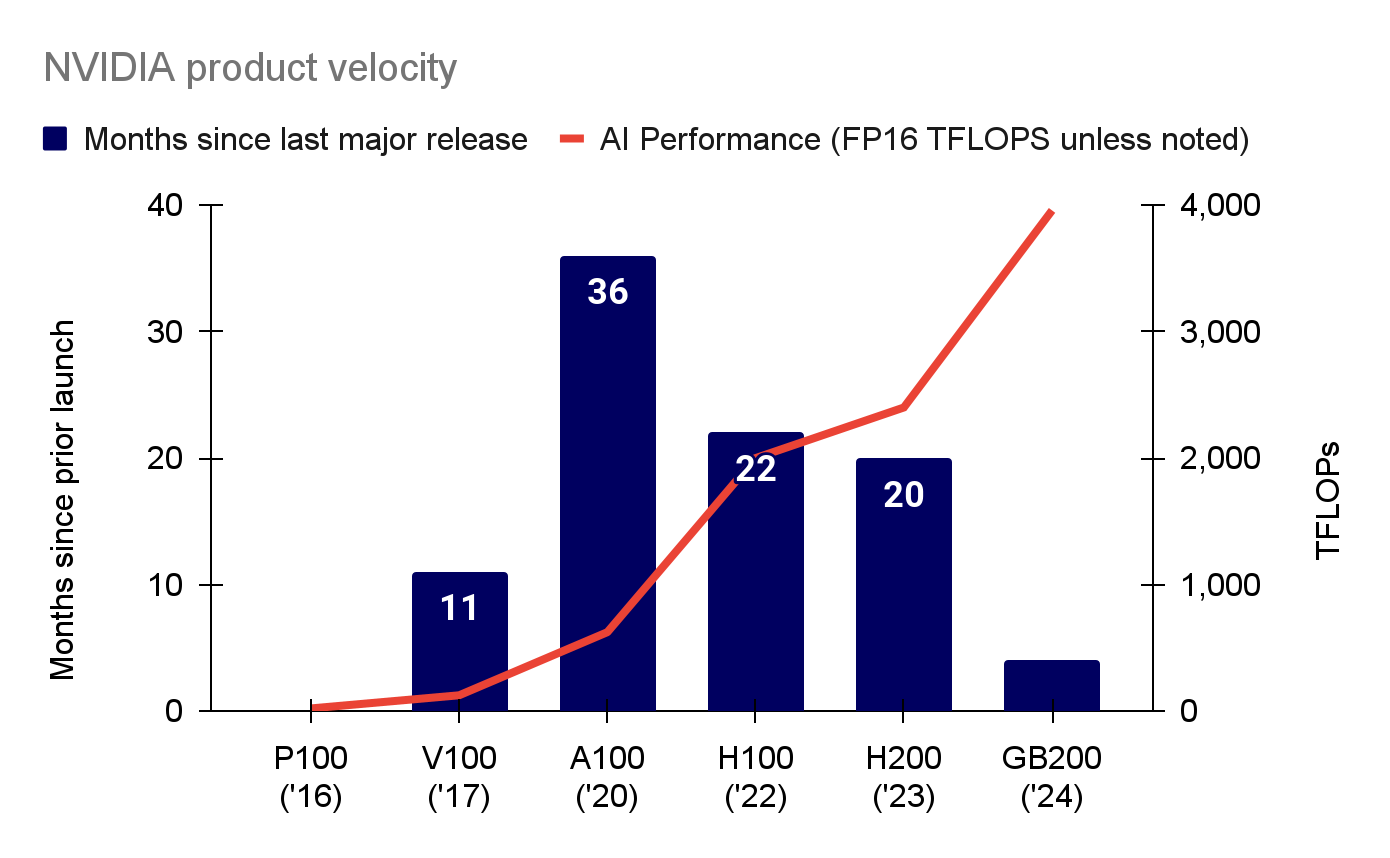
图:英伟达加速其产品发布时间同时提升TFLOPs性能
加快GPU与节点间连接提升集群性能
对于大规模集群,GPU和节点间(纵向和横向扩展)数据通信的速度至关重要。英伟达的NVLink技术在过去8年间大幅提升了带宽、链路数量和每个节点的GPU数量,显著提升了集群性能。此外,英伟达还通过InfiniBand技术连接大规模集群,进一步巩固了其市场领导地位。与此同时,国内的腾讯也在积极创新,推出星脉2.0高性能计算网络,声称支持超过10万个GPU的单集群,网络通信效率提升60%,LLM训练性能提升20%。不过,腾讯是否已经构建如此规模的集群仍未可知。
大型集群管理面临挑战
尽管集群规模在不断扩展,但运行大型集群仍然充满挑战。Meta在发布Llama 3系列时,分享了在405B预训练期间每天多达8.6次的工作中断。GPU比CPU更容易发生故障,且每个集群的情况也不同,因此持续监控非常关键。错误配置、测试不充分和故障组件常常影响系统的稳定性,而低成本电源和网络速率的可用性也至关重要。
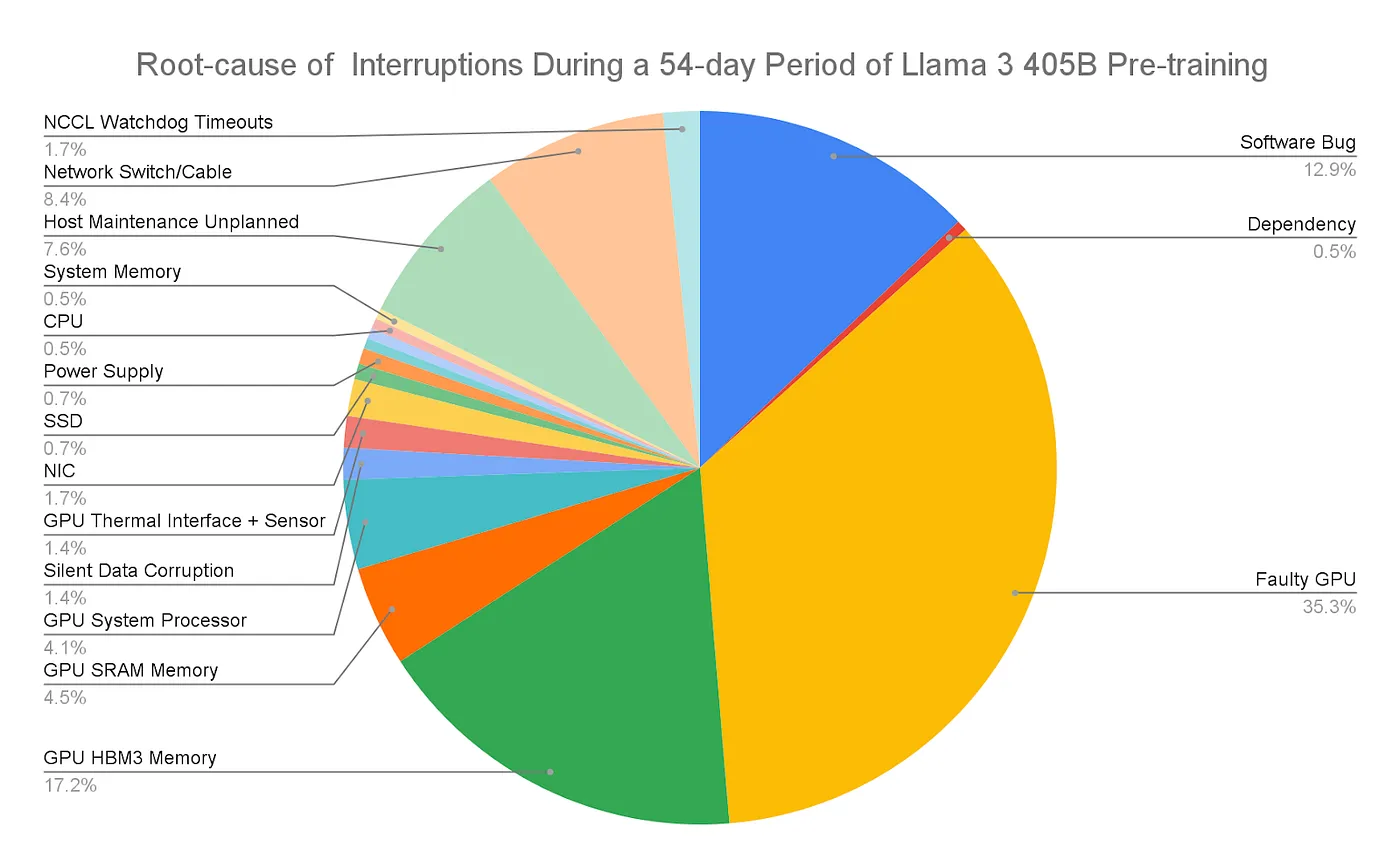
图:大型集群管理面临挑战
大型科技公司加速硬件自主研发,削弱对英伟达依赖
为了提升与英伟达的竞争能力,许多大型科技公司加速了自主硬件的研发。例如,谷歌推出了基于Armv9架构的Axion芯片,性能比现有最快的Arm通用实例高出30%。Meta则推出了第二代AI推理加速器,计算和内存带宽是前代产品的两倍,计划未来用于生成AI的训练任务。OpenAI也在从Google的TPU团队招募人才,并与高通商讨共同开发新一代AI芯片。
AI芯片领域的挑战者崭露头角
随着英伟达的主导地位,AI芯片的挑战者也在积极争夺市场份额。Cerebras以其晶圆级引擎而闻名,已计划IPO,并在2024年上半年实现1.36亿美元收入,增幅达到15.6倍,87%的收入来自总部位于阿布扎比的G42。Groq则专注于人工智能推理任务的专用芯片,最近完成了6.4亿美元的D轮融资,估值达到28亿美元。Cerebras和Groq都以速度为核心竞争力,并积极进入云服务市场,力图在英伟达的生态系统中抢占一席之地。
软银进军AI芯片市场
软银也在加速进入AI芯片市场,旗下Arm公司计划在2025年推出首款AI芯片,并有可能以600-700亿美元收购英国初创公司Graphcore。Arm虽然已在AI领域有一定参与,但其指令集架构并不完全适合数据中心的并行处理需求,且面临英伟达在数据中心的优势。软银同时收购了Graphcore,这家公司专注于开发智能处理单元,旨在用更少的数据比GPU和CPU更高效地处理AI工作负载。
相关阅读:




