

2024年人工智能全景报告由stateof.ai发布,是一份关于人工智能最新进展的综合分析报告。这份报告涵盖了人工智能领域的众多方面,例如:基础模型、AI硬件、AI与安全伦理、AI应用等。本次市场调查报告将带来关于2024年人工智能全景报告的解读。
大型语言模型(LLM)的突破
在过去一段时间里,GPT-4在人工智能语言模型的性能上遥遥领先,基准测试和社区排行榜都显示出GPT-4与其他模型之间有显著的差距。然而,随着Claude 3.5 Sonnet、Gemini 1.5和Grok 2等新模型的发布,这些竞争对手的表现有了显著提升,现在它们的性能已经接近GPT-4,缩小了原本存在的差距。根据State of AI,现在得的大型语言模型普遍具备较高的编程能力水平,在事实记忆和数学相关方面表现得较强。但在开放性问答和多模态问题解决方面表现稍显不足。例如,GPT-4o在MMLU基准测试上表现优于Claude 3.5 Sonnet,但在设计更具挑战性的MMLU-Pro基准测试上则表现稍逊。
考虑到架构之间相对微妙的技术差异以及预训练数据可能存在的大量重叠,模型构建者现在越来越需要在新的能力和产品特性上进行竞争。

图:Claude 3.5 Sonnet、Gemini 1.5和Grok 2等新模型的发布缩小与Open AI 的差距
2024年9月13日,Open AI发布了o1大模型,“o1”这个名字是为了表示“将计数器重置为1”,意味着OpenAI希望通过这个模型,重新定义人工智能的推理能力,开启一个新的纪元。o1也被称为Strawberry,该模型突破了LLM推理极限,自带COT(思维链)过程,弥补了先前的模型在数学、科学和代码方面的不足。
根据State of AI,通过将计算从预训练和后训练阶段转移到推理阶段,o1模型以链式思考(COT)的方式逐步推理复杂的提示,并运用强化学习来优化COT及其所使用的策略。这解锁了解决多层数学、科学和编程问题的可能性,而这些领域历来是大型语言模型(LLMs)因基于下一个词预测的固有限制而难以攻克的。
OpenAI报告称,与4o相比,o1在侧重于推理的基准测试上取得了显著进步,其中在数学竞赛AIME 2024上的表现最为突出,得分高达83.83,而4o仅为13.4。然而,这种能力的提升代价高昂:o1预览版的100万输入代币成本为15美元,而100万输出代币则需60美元。这使得其成本比GPT-4o高出3到4倍。
OpenAI在其API文档中明确指出,o1并非4o的直接替代品,对于需要持续快速响应、图像输入或函数调用等任务,它并非最佳模型。

图:Open AI o1 大语言模型测试
根据State of AI,开发者们很快就对o1进行了测试,发现它在某些逻辑问题和谜题上的表现明显优于其他大型语言模型。然而,它真正的优势在于复杂的数学和科学任务上,网上火热流传的一个视频是这样的:视频中一位博士惊讶地发现,o1在大约一个小时内复现了他一年的博士代码。然而,该模型在某些空间推理方面仍然较弱。像之前的4o一样,它还无法下棋。
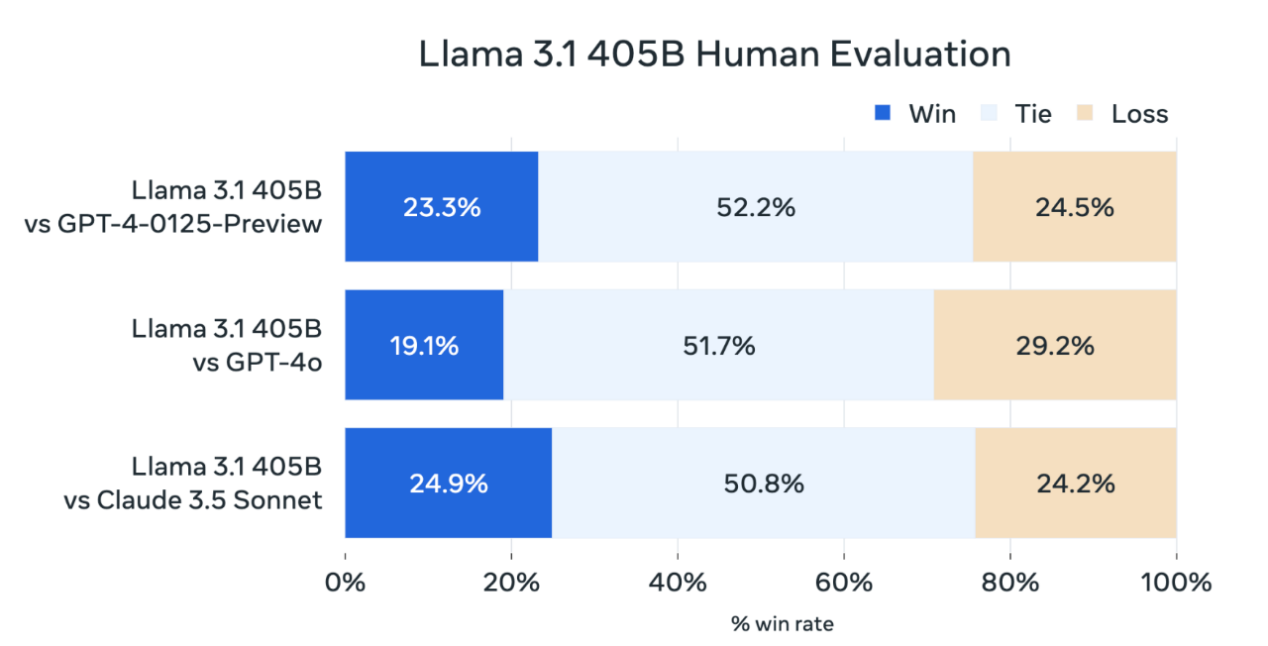
图:Llama 3.1大语言模型与其他大语言模型参数对比(图源:State of AI)
除了Open AI,其他科技巨头的大预言模型也取得了一定的进步。例如:今年4月,Meta发布了Llama 3系列模型,然后在7月发布了Llama 3.1,9月又发布了Llama 3.2。其中,Llama 3.1是截至目前他们最大的模型,参数达到405B(即4050亿),在推理、数学、多语言和长文本上下文等任务中,它能够与GPT-4o和Claude 3.5 Sonnet相抗衡。这标志着开源模型首次缩小了与专有前沿模型之间的差距,是开源模型领域的一个重要里程碑。
相关阅读:




